LAB
研究室
デモプログラム
ShaderModel2.0でGPU曲面分割
ShaderModel2.0でGPU曲面分割
今回は技術的なお話というよりかは実験的なおはなしです。
近年のGPUでは曲面/再分割が可能になったり、一般的な計算も可能になったりと表現力のポテンシャルはどんどん向上しています。
DirectX11/OpenGL4はできる事が増えた分、より高度で面白いプログラムが書けるようになっています。
新しい環境は大歓迎したいところではありますが、そこで問題になるのは「今までの環境とどう互換を取っていくのか」という部分です。
特にPC環境では、ユーザーによってPC性能や機能の差が大きく異なるため柔軟にサポートしていく必要があります。
次々とGPUに機能が搭載されていく中、過去の世代のGPUでテセレータを搭載していないものでもGPU支援で曲面や再分割できたりしたらDirectX11っぽくて面白そうだな、と思い立って作成してみました。
「DirectX9 ShaderModel2.0世代でGPUポリゴン分割レンダリング」が今回のお題です。
GPUで実行するからにはCPU負荷をかけないことを目標にします。

このテセレーション自体はかなり以前の世代のShaderModel2.0でも動作可能です。
法線生成など他の実装を含めるとテンポラリレジスタ数制限によってオーバーしてしまいましたので今回はSM3.0と2種類で実装してみました。
SM2.0対応GPUではテセレートとテクスチャマッピングが実行され、SM3.0以降対応GPUならさらに高品質に法線生成して描画されます。
下記よりダウンロード可能です。
◎動作可能な環境
<動作条件>
WindowsXP以降 DirectX9 ShaderModel2.0以上対応のGPU
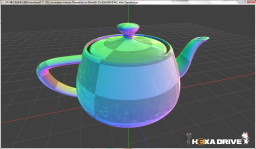
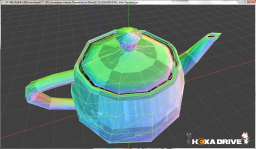
【左】高精細な分割 【右】 粗い分割
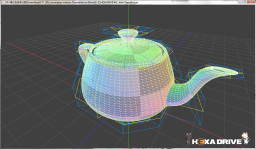
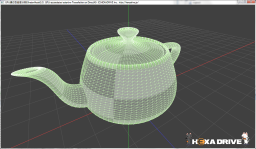
【左】SM30の実行結果 【右】 SM20の実行結果
Download
HexaTessellation.zip (約2.47MB)
【動作確認済ハードウェア】
NVIDIA GeForce GT 420
【操作方法】
マウス左クリック&ドラッグ……視点回転
Z ……曲面パッチコントロールポイント表示 ON/OFF
X ……ジオメトリワイヤーフレーム表示 ON/OFF
C or V ……テセレーション係数増減(分割数が変化)
◎実装のポイント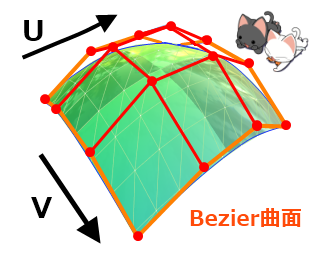
当初からテセレータを搭載していたGPUは存在しており、DX9内でも限定的に使用できるものもありましたが、すべてのGPUが対応していたかというと実はそうではなく、各個別に対応する必要があることと非搭載の環境では互換をどのようにするのか。という課題がありました。
DX11からは共通のGPU仕様として導入されていますので安心して使えますよね。
DX11はテセレートされたあとのジオメトリは通常のポリゴンとして取り扱えますのでDomainShader上でさらなる加工も可能です。
ポリゴンを分割することをCG用語でTessellation (テセレーション/テッセレーション)と呼びます。
英単語的意味は「モザイク細工、モザイク配列、 埋め尽くし」などの意味があります。
頂点シェーダではテセレータユニットのように分割ができませんので文字通りポリゴンを並べて埋め尽くそう!というのが今回のアイデアです。
DX9環境ではこれらの実装を全て頂点シェーダー内でやってしまいます。


ここで実装のポイントとなるのがGeometryShaderやテセレータの機能である
「頂点座標をGPU内で新規生成して三角形データとして投入する」機能がDX9世代には存在していないことです。
なかでもATI(現AMD) RadeonなどはDX9世代でもテセレータ対応していたりします。
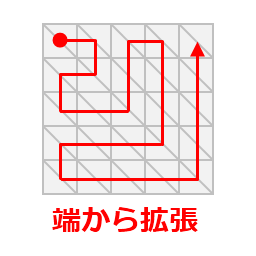
そこで、予め生成される予定の最大個数分の頂点を頂点バッファ上に作成しておき、必要個数分をDrawPrimitiveの描画プリミティブ数に指定することで増減させます。
ここは最大個数分を頂点バッファ上に持つことで冗長性が出てしまいます。
CPUを使わずに全てGPUのみで完結させることを目標にしましたが、この描画ポリゴン数だけシェーダー側からは動的にはできないためなるべく負荷をかけないようにCPU上でおおまかに計算しています。
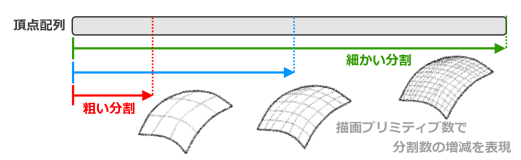
ここはCPU負荷を最小にとどめるため、厳密に数を計算せずに大雑把な精度で求めています。多少の範囲外頂点は頂点シェーダー内でクリップします。
(そのぶん若干頂点シェーダー後のカリングに負荷がかかりますが…)
この頂点の持たせ方によって、様々なテセレーションアルゴリズムが表現可能です。

プリミティブ用の頂点には曲面位置のUV値に相当するパラメータを事前に格納しておきます。
頂点シェーダー内で頂点座標を生成するためここには頂点座標情報は不要です。

曲面パッチ情報は頂点バッファの中に仕込みます。
これがDX11とは異なり冗長なデータになってしまう部分の一つです。
SM3.0ではHWインスタンシングなどを使えば効率的に共有データを保持できます。
SM2.0では定数レジスタにセットして使用するかしなければレジスタ個数が不足します
ので描画が曲面パッチ単位になったりとさらなる制限がつきます。
◎適応型テセレーション (Adaptive Tessellation)
せっかくなので、分割数を適応化分割してみます。
テセレーションすると、曲面パッチ同士で繋ぎ目の分割数が異なると隙間(クラック)が発生してしまいます。
これを回避するために隣接する曲面の境界線は分割数を一致させることで対応できます。
今回はコントロールポイントの位置のビュー空間のZ座標で分割数をコントロールしました。
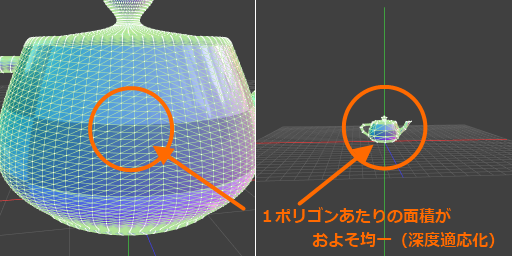
これによって距離によってのポリゴンあたりの面積が均一になり、効率的なLODが可能になります。
この実装はDX11でもSDKサンプルのDetailTessellation11などでも見ることができます。
一部の辺の境界線に分割数適応化を実装しています。シームレスにジオメトリが接続されています。
今回のデモのポットだと側面の部分に適用されています。

今回のデモではテセレート処理が完全な実装にはなっていないため、分割数適応されていない部分で分割数が異なる部分には
縮退ポリゴンを挿入してクラックが見えないように対処してあります。
これは頂点シェーダーの分割アルゴリズムを改良すれば解決できそうです。後日実験してみようかなと思います。
法線方向を見てシルエットになる部分だけを高精細にする適応化なども対応できそうです。
今回はDirectX11を使わずにGPUテセレーションを実装してみました。
テセレータ非搭載のGPUでも動作しますので何かの表現に使えるかもしれませんね。
DirectX11ではこれらすべてがハードウェア化され更に高効率になり、分割数もこれよりもさらに細かくしても低負荷でワイヤーフレーム表示が真っ白な塊になって見えるレベルまで再分割できます。
ポストエフェクトフィルタも従来のピクセルシェーダーではなくComputeShaderで実行できますので、よりスマートに高速に作成できます。
DirectX11での最新技術のデモも今後公開していく予定です。
CATEGORY
- 製品事例 (7)
- デモプログラム (18)
- プログラムTIPS (42)
- C言語 (5)
- C++ (6)
- C++cording (4)
- Ruby (8)
- VisualStudioの使い方 (3)
- 最適化Tips (5)
- ゲーム開発テクニック (3)
- その他 (7)


